Hadoop
: 복수의 서버를 묶어서 하나의 가상 서버로 사용할 수 있도록 하는 것.

■ 분산 파일 시스템과의 강한 연계를 통해, 높은 스루풋(Throughput) 처리를 실현하는 분산 처리 소프트웨어
: Hadoop은 크게 두 가지 구성 요소로 이루어져 있다. 하나는 분산 파일 시스템으로, 대용량 데이터를 복수의 서버에 저장하는 구조다. 복수의 서버를 조합해서 사용자에게 하나의 큰 파일 시스템을 제공한다. 다른 하나는 병렬 분산 처리를 실현하는 프레임워크다. 이것은 하나의 큰 처리(잡, job)를 복수의 단위(태스크, task)로 분할해서 실행하는 구조다. 이 분산 파일 시스템과 병렬 분산 처리 프레임워크가 공고히 연계되며, 높은 스루풋의 데이터 처리를 실현한다. 기술적인 관점에서 Hadoop을 한마디로 표현하면, '분산 파일 시스템과 강한 연계를 통해 높은 스루풋 데이터 처리를 실현하는 분산 처리 소프트웨어'라고 할 수 있다.
■ 자바(java) 기반으로 개발되어 일반적인 서버에서 동작
: 언제나 구할 수 있는 장비로도 구축이 가능
■ 서버를 추가하면 용량과 성능이 향상(스케일 아웃, Scale-out)
: 서버 자체의 성능을 올리는 스케일 업(Scale-up) 방식으로는 성능을 올리는 데 한계가 있으므로, 서버 대수를 증설하는 스케일 아웃 방식이 가능
■ 관계형 데이터베이스나 검색 엔진과는 다름
: 관계형 데이터베이스는 정규화된 작은 데이터 세트에 대해 낮은 대기 시간을 가지고 엑세스하도록 만들어졌다. 하지만 hadoop은 대량의 데이터를 대상으로 일괄 처리를 실행한다. Transaction 제어 등의 기능도 없다. 검색 인덱스를 만들 때 자주 사용되나, 검색 요청에 바로 응답할 수 있는 검색 엔진 소프트웨어는 아니다.
■ 가장 활발한 오픈 소스 프로젝트
: 아파치 라이선스로 공개되어 있으며 현재 가장 활발한 오픈 소스 프로젝트 중 하나이다.
◆ Hadoop의 용도
: IT 자산 관리를 위해 사용되고 이쓴ㄴ 일괄(Batch) 처리 변경이다. 높은 비용으로 포기했던 처리를 현실적인 비용으로 구현이 가능하게 되었다.
◆ Hadoop의 탄생
: 기존 데이터 저장 체계로는 한계가 있었기 때문에 구글에서 대량의 웹 사이트 데이터를 저장하고 처리할 수 있는 미들웨어를 자체적으로 개발하여 사용하기 시작했다. 이 기술 중 일부가 2003년 <The Google File System>, 2004년 <MapReduce:Simplified Data Processing on Large Clusters>라는 두 가지 논문을 통해 발표되었고 이는 철저히 베일에 가려져 있떤 검색 엔진 기반 기술이 드디어 세상에 공개되고 이 논문을 통해 발표된 기술적 아이디어를 바탕으로 하여, 오픈 소스로 구현하기 시작되었다.
■ Hadoop과 구글 기술과의 관계

■ 병렬 분산 처리 시스템

대규모 데이터 처리의 문제점과 대응
■ 시스템이 취급하는 데이터 규모의 증가
: 각종 SNS등의 발달로 정복 폭발이라는 개념이 생겼고, 2020년에 전 세계에서 만들어지는 데이터양은 35ZB에 달할 것으로 예측하고 있다.
킬로 -> 메가 -> 기가 -> 테라 -> 페타 -> 엑사 -> 제타
■ 대량의 데이터를 처리하기 위한 구조


Hadoop은 다음의 기능을 미들웨어로서 제공한다
˚ 복수의 하드디스크나 서버를 동시에 이욜할 수 있는 구조(높은 처리량으로 데이터를 읽어 들여 병렬 처리한다.)
˚ 분산 처리에 반드시 필요한 공통 기능 제공(태스크 분할, 실패 시 복원 등)
Hadoop 적용 분야
◆ 만능 제품이 아니다
Hadoop은 대용량 데이터에 특화된 미들웨어지 만능 제품은 아니다. 물론 Hadoop은 RDBMS도 아니기 때문에 오히려 대용량 데이터 처리를 위해 희생하고 있는 기능도 많다. 결론부터 말하면 Hadoop 적용 분야는 '테라바이트 또는 페타바이트 급의 데이터를 위한 일괄(Batch) 처리'다.
◆ RDBMS와 Hadoop 비교
Hadoop 특성을 설명할 때, 기존 RDBMS와 비교하면 이해하기 쉽다. 여기서는 표 1.2의 다섯 가지 관점에서 비교하겠다.

■ 1. 다루는 데이터 크기
■ 2. 데이터 조작
■ 3. 응답 시간(Latency)

■ 4. 서버 대수와 성능 향상

■ 5. 데이터 구조(구조화 데이터/준 구조화 데이터)
◆ Apache의 Hadoop 프로젝트
◆ 서버 구성 echo-system


linux에서 Hadoop을 설치한 것을 가지고 하둡을 활용해 보자






































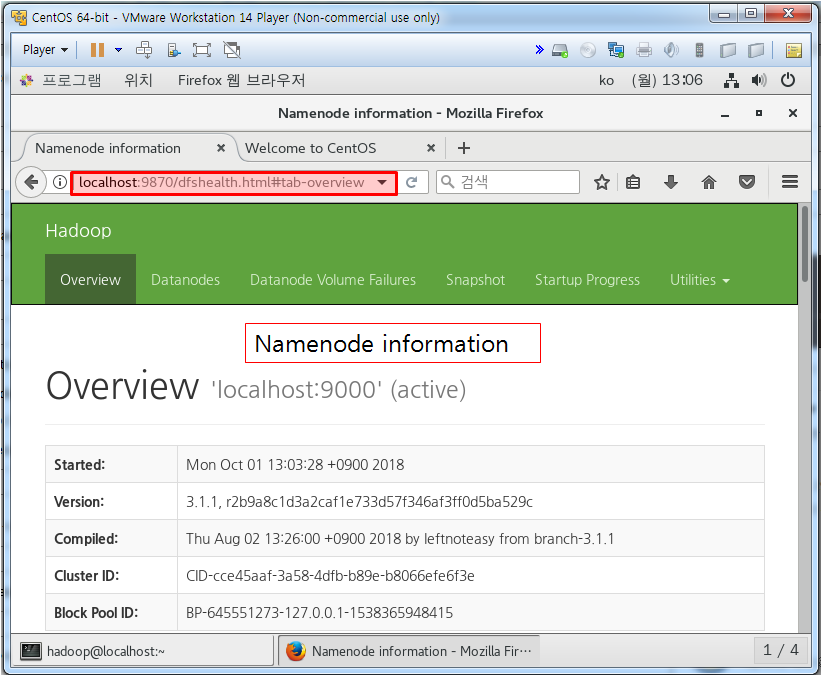



'Web & Mobile > Hadoop' 카테고리의 다른 글
| Lecture 93 - Hadoop(3) 3개 서버 연동하기 (0) | 2019.08.13 |
|---|---|
| Lecture 92 - Hadoop(2) 기초, Yarn 서버 추가법 (0) | 2019.08.12 |
| Linux CentOS에 Hadoop 설치 방법 (0) | 2019.08.08 |



댓글