반응형
hadoop에서 Python 사용하기









Project Assignment WordCounting in Python and Hadoop
1. python - 구글링
사이트 -> 워드카운트하는 프로그램 짜기
- 워드문서
- 소스
2. hadoop - standalone
사이트 -> 워드카운트
- 워드문서
-> 스크린샷
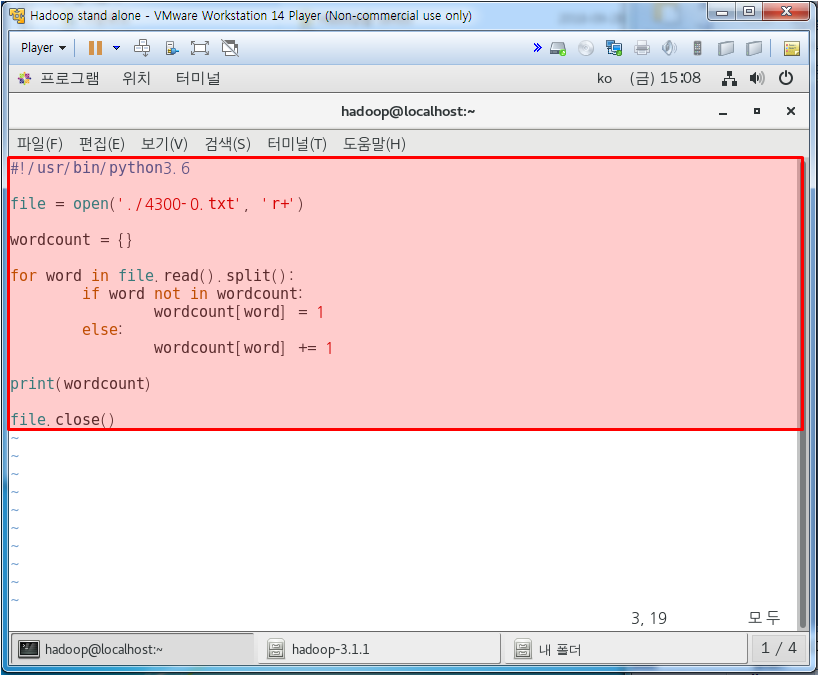
1. Python Word Count
'''
Created on 2018. 10. 5.
@author: kitcoop
'''
import re
with open('C:/Python/eclipse-workspace/AssignmentEx01/4300-0.txt', 'r', encoding='utf-8-sig') as file:
data = file.read()
# 정규식 사용 해당 문자를 공백화 하기
# re.sub(pattern, repl, string) - string에서 pattern과 매치하는 텍스트를 repl로 치환한다.
words = re.sub(r'[-—,.?!:]', '', data)
# 대문자를 소문자화
words = words.lower()
# print(words)
word_list = words.split()
# print(word_list)
# 딕셔너리 초기화
d={}
for word in word_list:
if word not in d:
d[word] = 0
d[word] += 1
# key와 value 위치 바꿈 - tuple화
word_freq = []
for key, value in d.items():
word_freq.append((value, key))
# count된 word 빈도수 높은순으로 정렬
word_freq.sort(reverse=True)
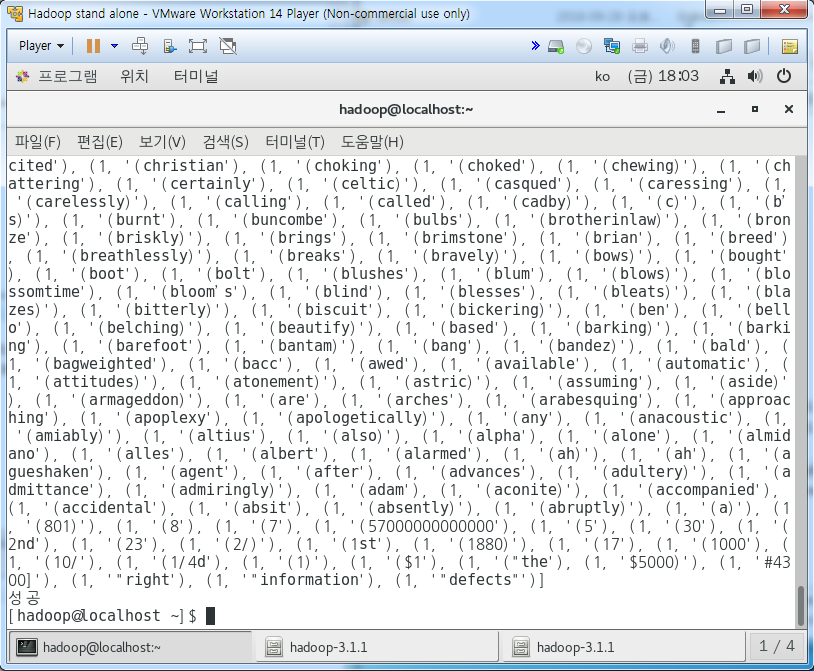
print(word_freq)
# 4300-1이란 text 문서로 출력
with open('C:/Python/eclipse-workspace/AssignmentEx01/4300-1.txt', 'w', encoding='utf-8-sig') as file2:
# 리스트를 String으로 변환
str1 = ',\n'.join(map(str, word_freq))
data2 = file2.write(str1)
print('성공')
file.close()
file2.close()


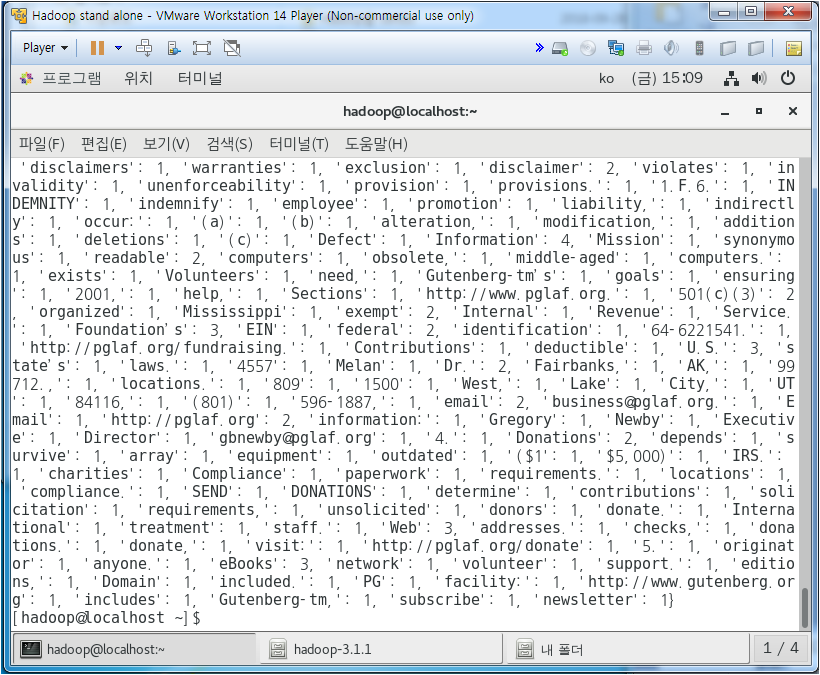
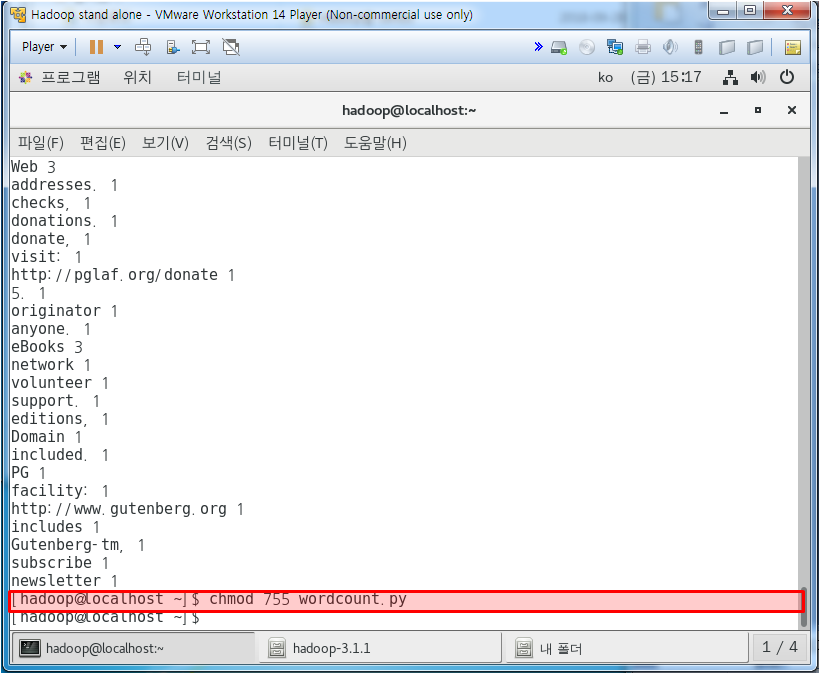
위와 같이 4300-1에 높은 빈도수대로 정렬된 결과를 볼 수 있다.
하둡에서 파이썬 실행해서 해보기




2. Hadoop Word Count
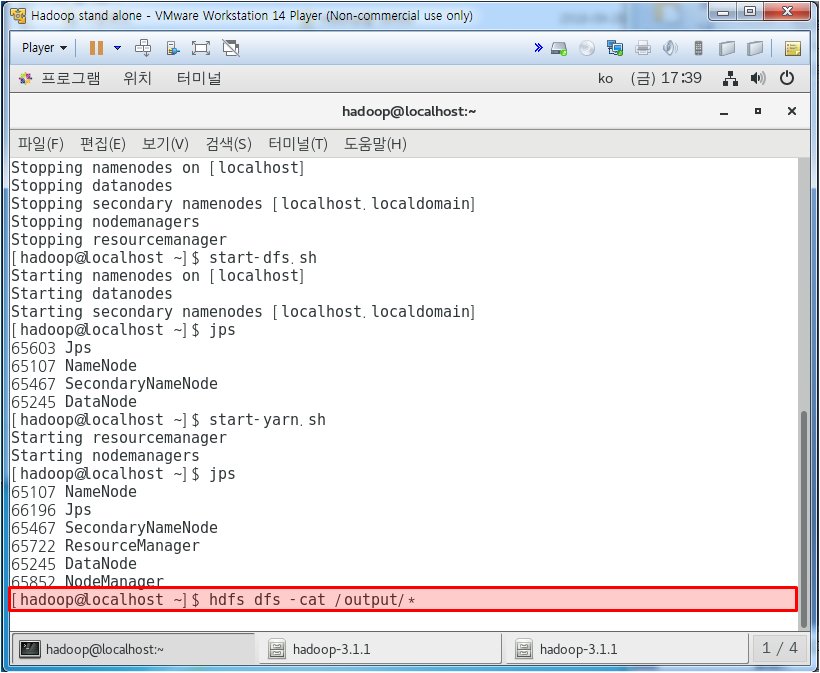
[hadoop@localhost hadoop-3.1.1]$ mkdir input
[hadoop@localhost hadoop-3.1.1]$ cp 4300-0.txt input/
[hadoop@localhost hadoop-3.1.1]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount input/* output
[hadoop@localhost hadoop-3.1.1]$ cat output/*
여기까지가 local에서 wordcount 하는법
Yarn 서버에서 wordcount 해보자





반응형
'Web & Mobile > Python' 카테고리의 다른 글
| Lecture 90 - Python(10) xml, html, json 처리법, 정규식 사용법 (0) | 2019.08.06 |
|---|---|
| Lecture 89 - Python(9) url 관련 함수들, 데이터 크롤링, geocoding을 이용한 위치 검색 (0) | 2019.08.05 |
| Lecture 88 - Python(8) 파이썬을 이용한 우편번호 검색기, nCloud에 python 3 설치 (0) | 2019.08.01 |
| Lecture 86 - Python(7) 파이썬에 데이터베이스 연결 (0) | 2019.07.30 |
| Lecture 85 - Python(6) 패키지, 내시스템정보확인, 시간, 날짜, webbrowser (0) | 2019.07.26 |




댓글