빅데이터 개념 : 3V
1. Volume(볼륨) : 데이터 크기(헥터바이트 이상의 크기가 나올때, 한개의 서버에 저장하지 못할때)
2. Velocity : 데이터 가공속도 (데이터 생성 속도)
3. Variety : 데이터의 다양성(데이터 내부에 생성되는 데이터의 종류가 다양함)
+2가지를 추가한다.
complexity
value(데이터에 대한 가치성 - 비쥬얼라이제이션(시각화))
=> 정규적인 형태의 데이터베이스에서는 처리 불가
=> scale-out 형태의 병렬 처리구조(클러스터링) 형태의 데이터 처리구조가 나음(HDFS)
=> hadoop
=> 대용량(빅) 데이터를 분산(병렬) 처리할 수 있는 자바 기반의 오픈 소스 프레임워크(서버)
=> google - GFS, Map/Reduce 논문이 나옴
=> HDFS, mapreduce 개념으로 실제로 구현이 된다. 요걸 뭉쳐서 (HDFS + mapreduce)
하둡 에코시스템
저장(HDFS) -> 처리(map/reduce)
데이터가 들어오면 잡트레커가 task tracker에게 나눠서 분산으로 저장한다. 그리고 그걸 다시
통합시키는 것이 reduce이다. 각자 분산할 때 서버가 있고, 그 서버들 위에 namenode라는 것이 있다.
그런데 namenode가 부서지면 안되니깐 secondary namenode가 있다.
하둡 분산구조
namenode : datanode 서버 관리
datanode : 실제 분산 데이터 저장
jobtracker : 작업에 할당 및 수집
testracker: 작업에 할당 및 수집
하둡 에코 시스템
: 하둡을 활용한 추가 시스템
https://www.bogotobogo.com/Hadoop/Big Data_hadoop_Ecosystem.php
https://hadoop.apache.org


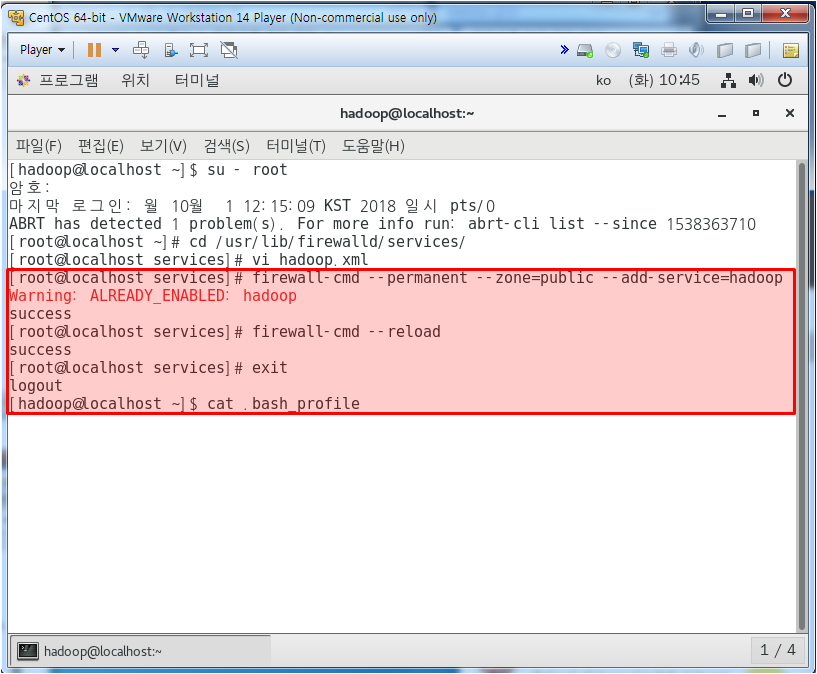

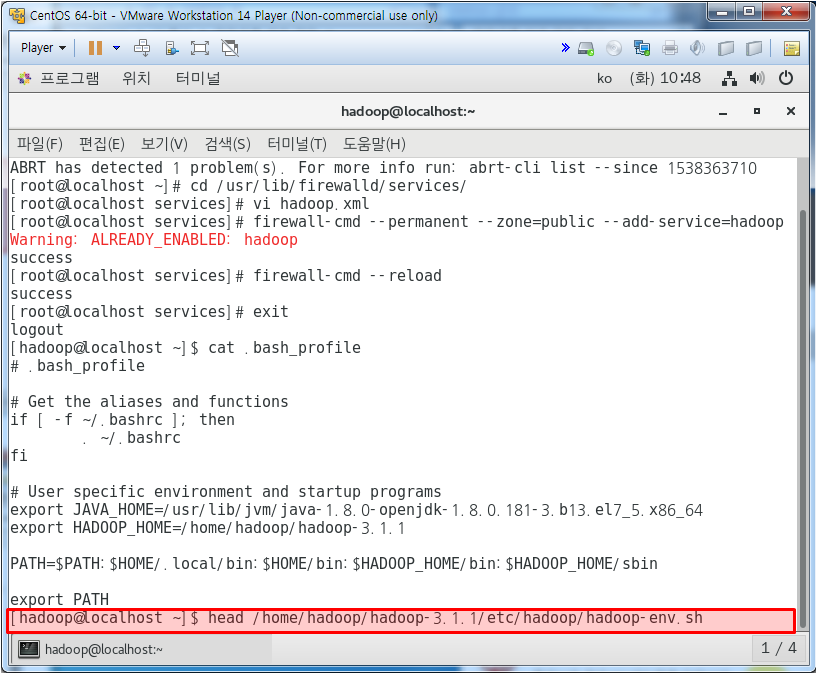

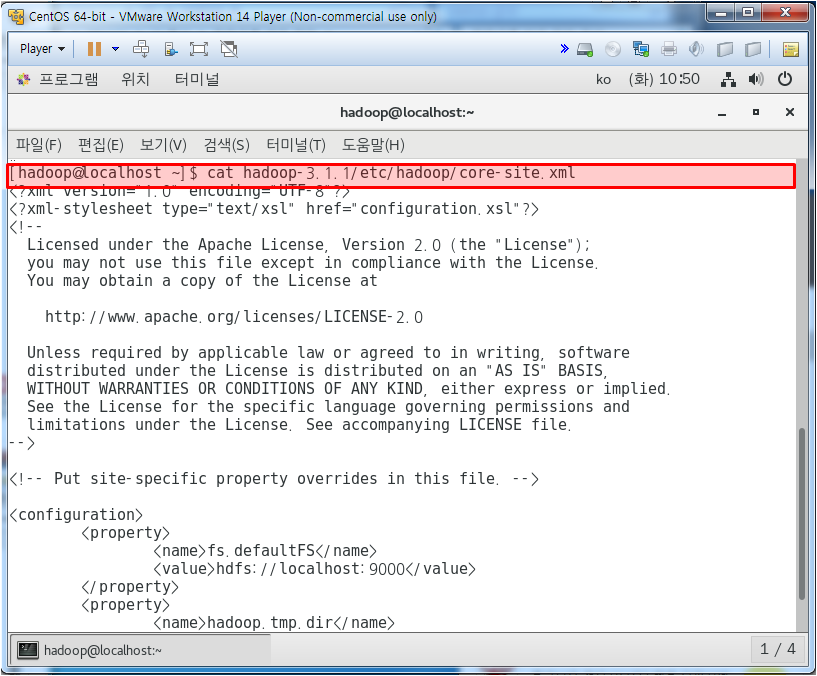
core-site.xml에서 하둡 설정되어 있는지 확인

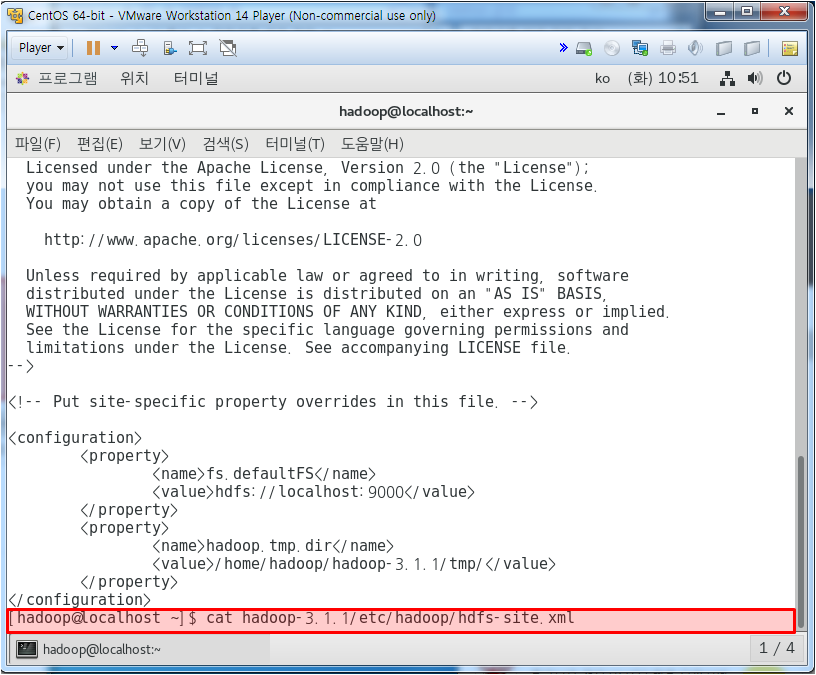
hdfs-site.xml에서 하둡 설정되어 있는지 확인
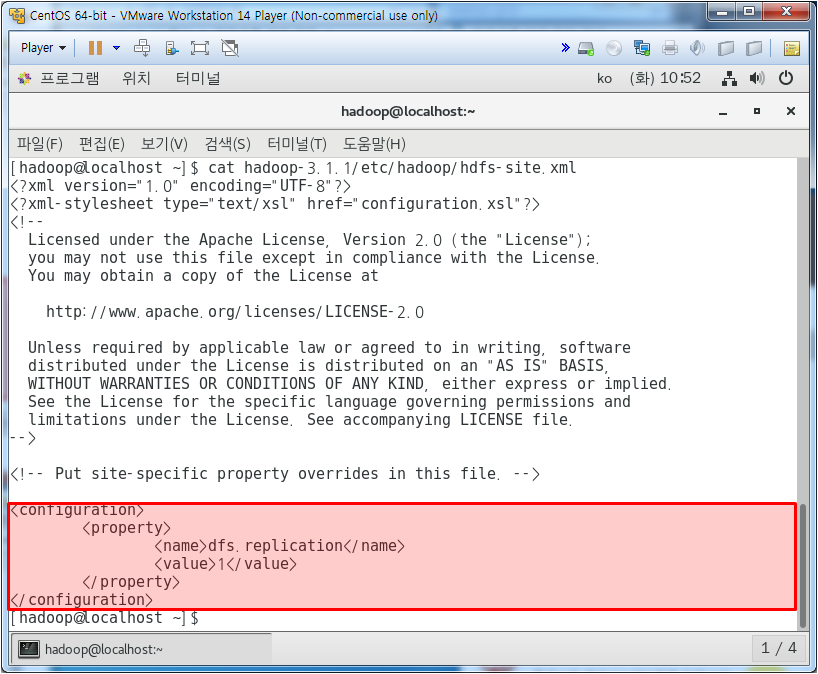
레플레케이션 값이 1이면 pseudo mode이고 3이면 multi mode이다.

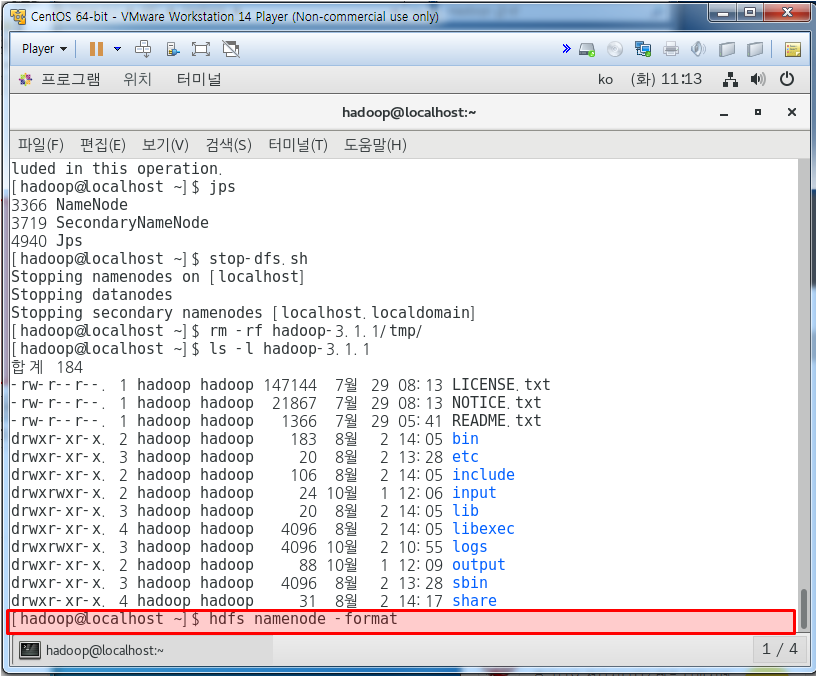
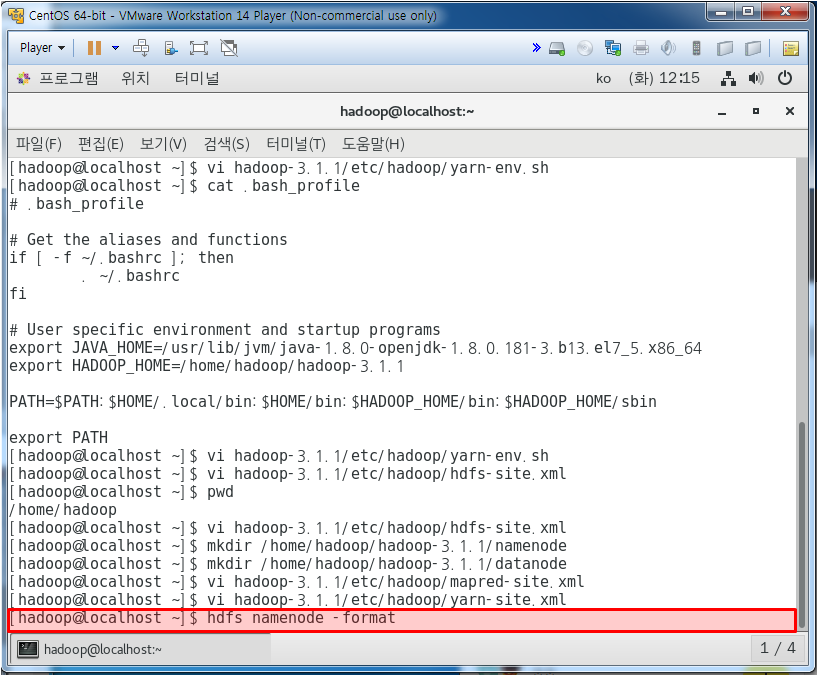
네임노드 초기화

하둡 시작

jps 치면 프로세스가 뜬다
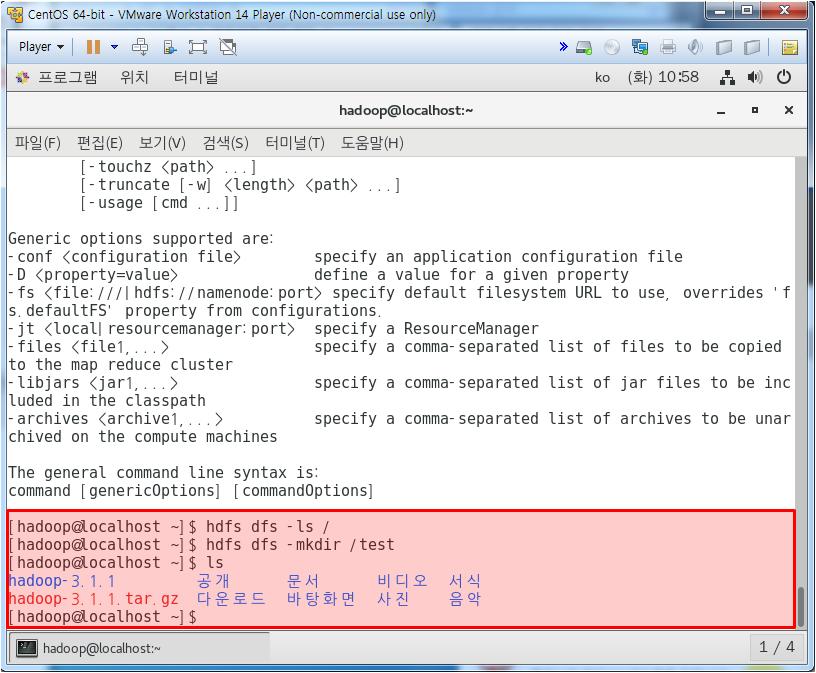
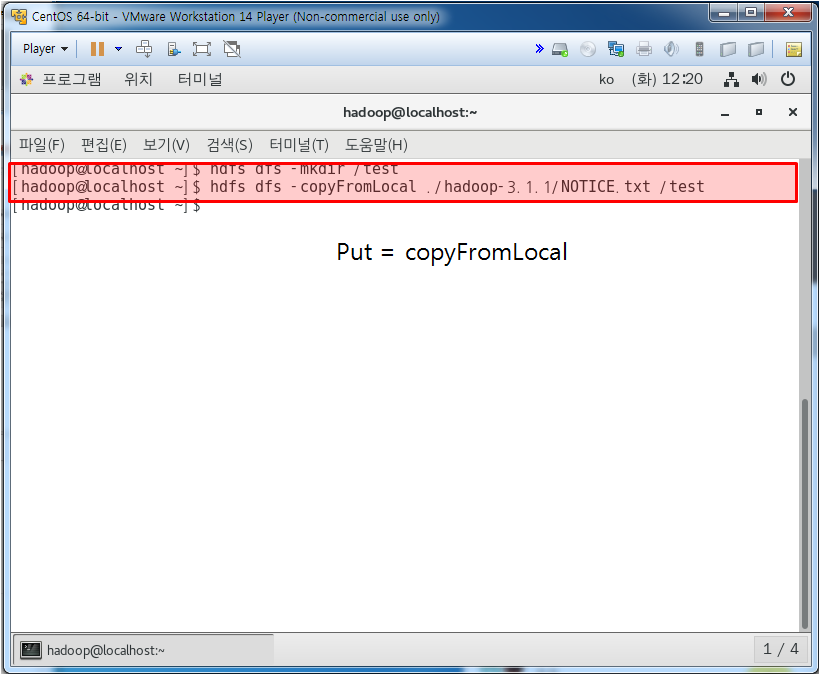
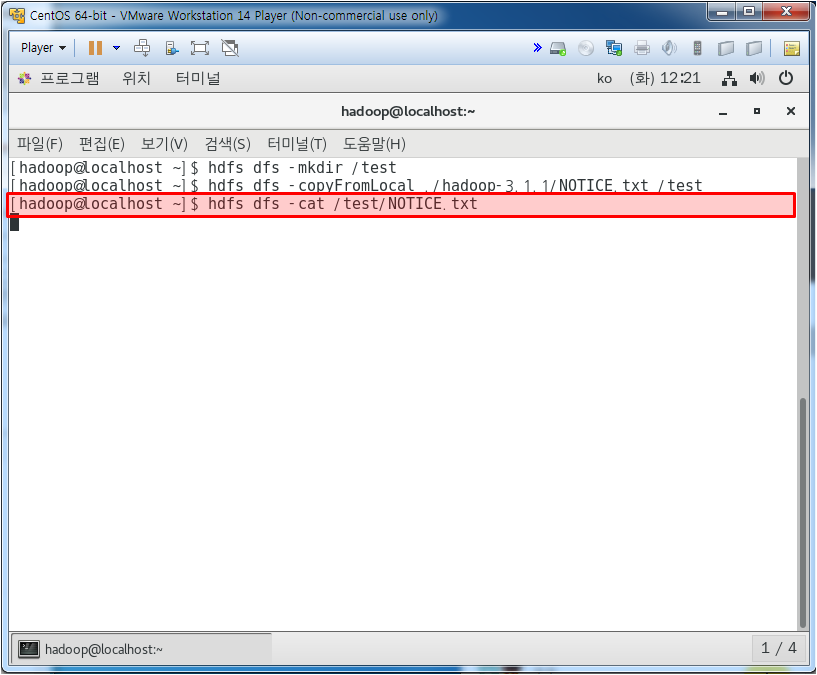
hdfs dfs ls / 를 치면 루트안의 내용을 보여주는데 지금은 아무 것도 없다. 그래서 그 안에 test 파일을 만들어주고 다시 ls를 하면 나오진 않는다. 하둡내 저장공간에 저장된 것이기 때문이다.


하둡 서버 크롬에서 들어가서 확인해 보면 위와 같이 test로 만든게 있는걸 볼 수 있다.


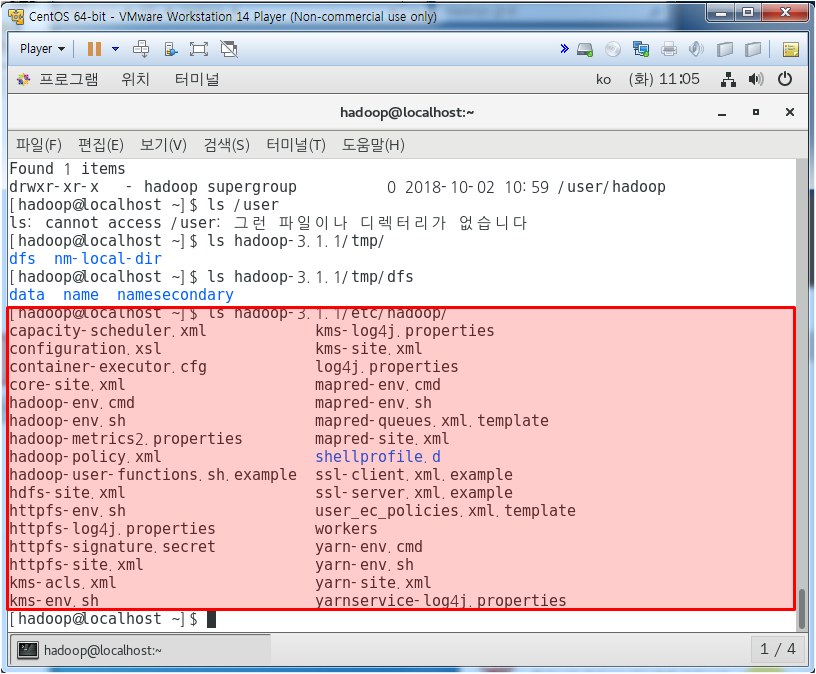
이 하둡 파일시스템을 /user/hadoop으로 옮겨보자


datanode가 없어서 에러가 난다. datanode가 가동이 안될 때 처리 방법은 아래와 같다.
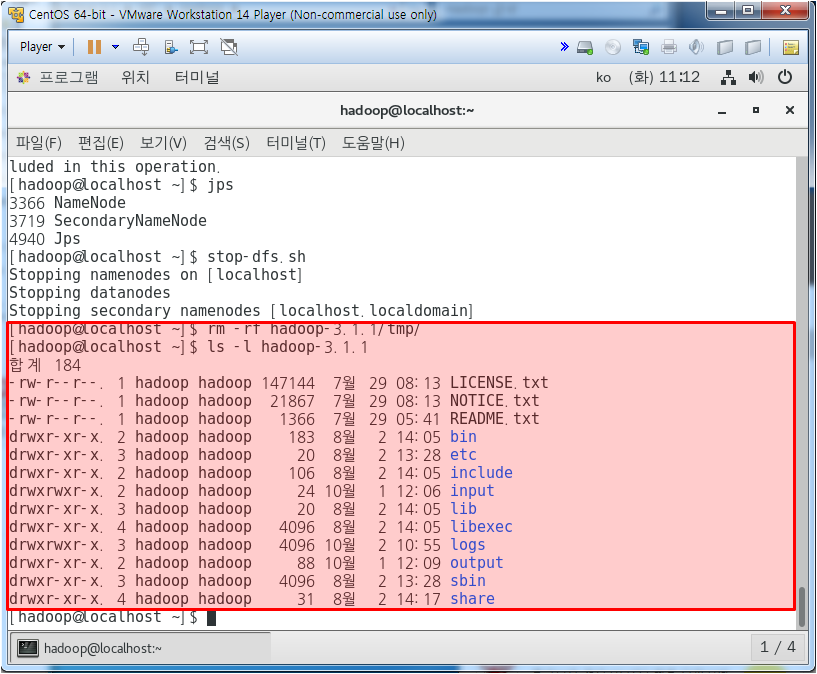
위와 같이 하여 tmp 파일이 없어야 한다.

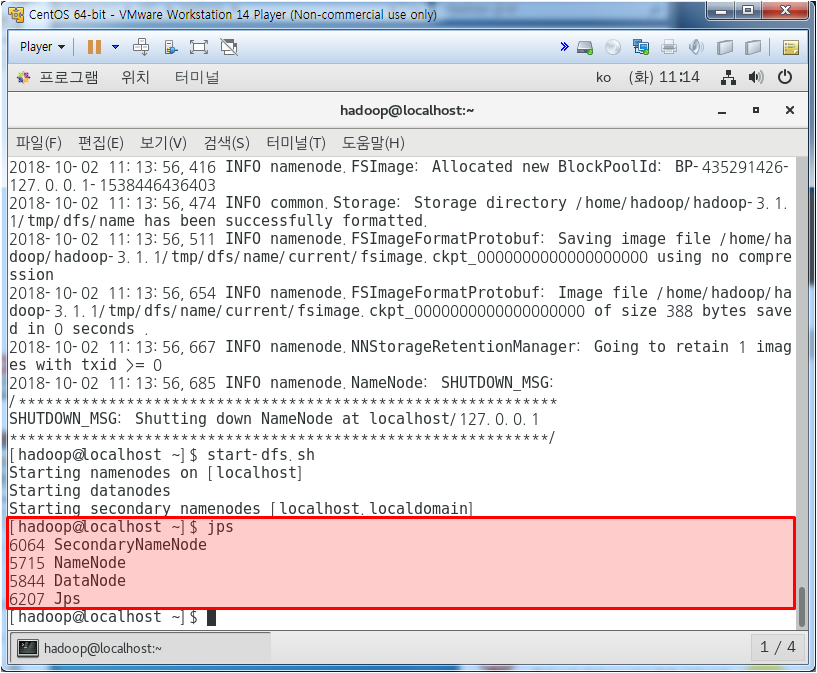
jps 하였을 때 DataNode가 보이면 성공이다.
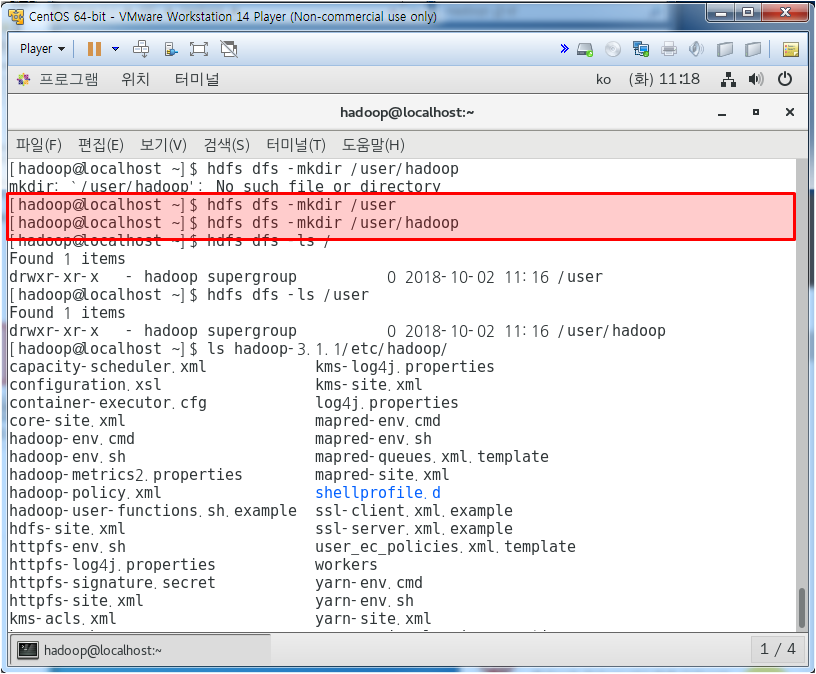
/user, /user/hadoop 디렉토리를 만들어 주고

/user/hadoop으로 hadoop 파일을 옮기고

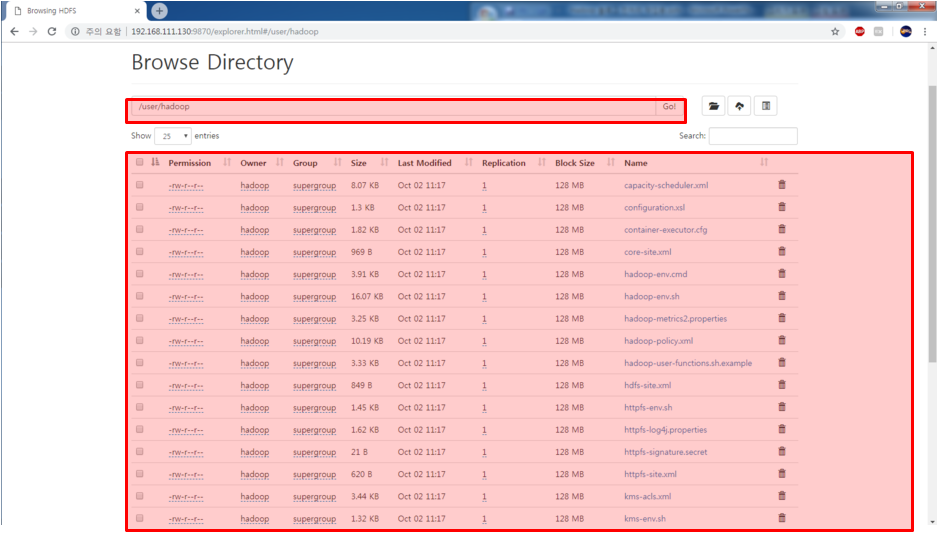
위와 같이 옮겨진 것을 확인할 수 있다.


위와 같이 read는 되는데 수정은 안된다.

shell로 시작되는 파일이 있는지 없는지 확인하고 있다고 떴으며 이를 지우고 다시 검색해서 없다고 뜸. 이를 이용하여 word count를 할 수 있다. 어제는 로컬 파일을 했다면 오늘은 하둡내 파일을 해보자.

/user/hadoop 에 있는 모든 파일중에 'dfs[a-z.]+' 조건을 충족하는 내용을 grep(찾기)으로 확인해보는 방법으로 이를 자바로 해보려고 하면 무수히 많은 구문들이 필요할 것인데 하둡으로 단 한줄로 위와같이 표현할 수 있다. 우편번호 검색처럼 하나 검색할때는 자바로 해도 문제가 없겠지만 수가 방대해지면 자바로 수많은 구문들을 작성하게 되면 효율이 떨어진다.
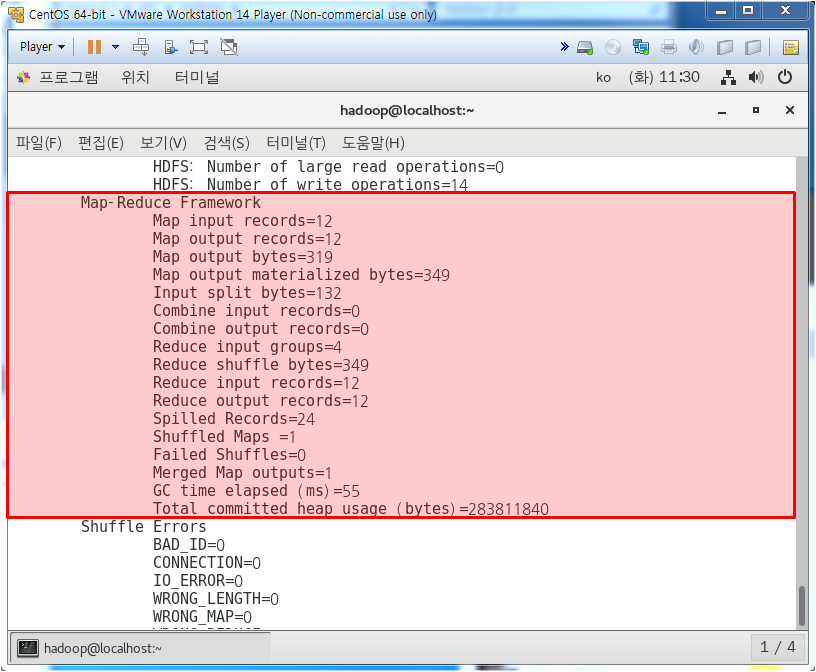
모든 파일들을 열어보며 위와 같이 검색하여 결과를 알려준다.
hadoop
jar
./hadoop-3.1.1/share/hadoop/mapreduce
/hadoop-mapreduce-examples-3.1.1.jar
grep
/user/hadoop
/output
'dfs[a-z.]+'
결과는 output에서 나오는데 그냥 ls하면 로컬위치이므로 안나오고 하둡 위치를 찾아서 검색해야 한다.

output/part-r-00000파일이 grep을 도출한 결과가 담긴 파일이다.
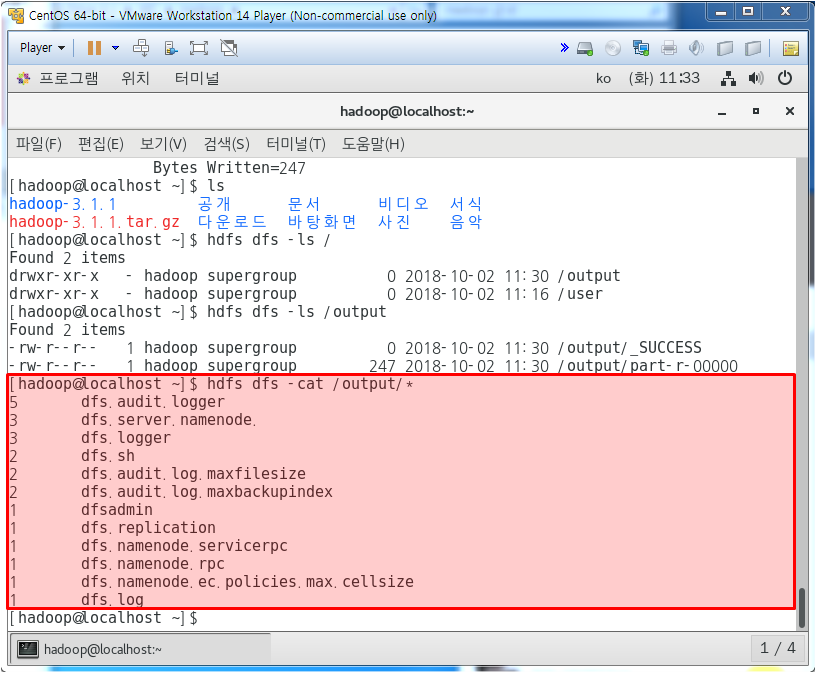
위와 같이 확인하면 정규식 조건에 부합하는 내용들을 확인할 수 있다.
이걸 이용하면 예를 들어 토익에서 출제가 잘 되는 빈도수가 높은 단어를 검색할 때 사용하기도 한다.
이제 이걸 외부로 뽑아보자

그냥 ls를 치면 output이라는 폴더가 생성이 되었다.
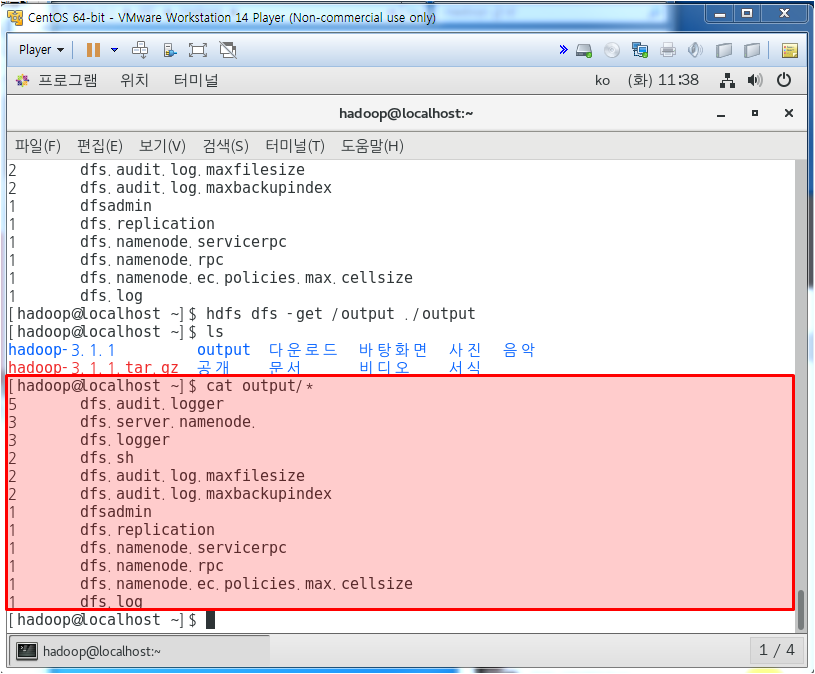
똑같은 결과가 나옴을 확인할 수 있다.
yarn 서버를 써보자

yarn 서버를 키지 않아서 8088은 안들어가진다.
yarn 설정을 해보자









서버를 띄어보자!

dsf 서버를 켜주고 이제 yarn을 따로 또 껴줘야 한다.
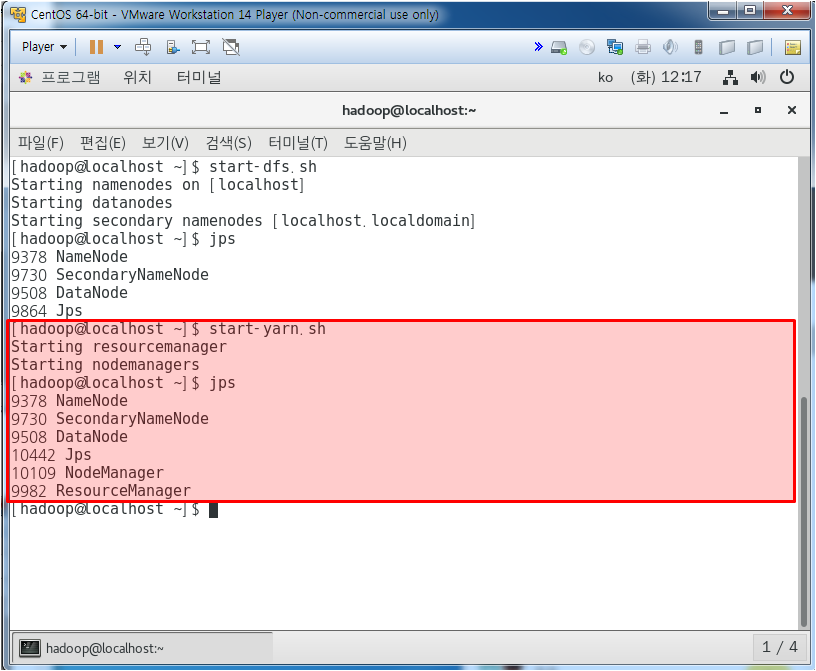

위와 같이 8088 Yarn 서버가 띄어졌음을 확인할 수 있다.
아까 했던 mapreduce를 Yarn을 이용해서 해보자

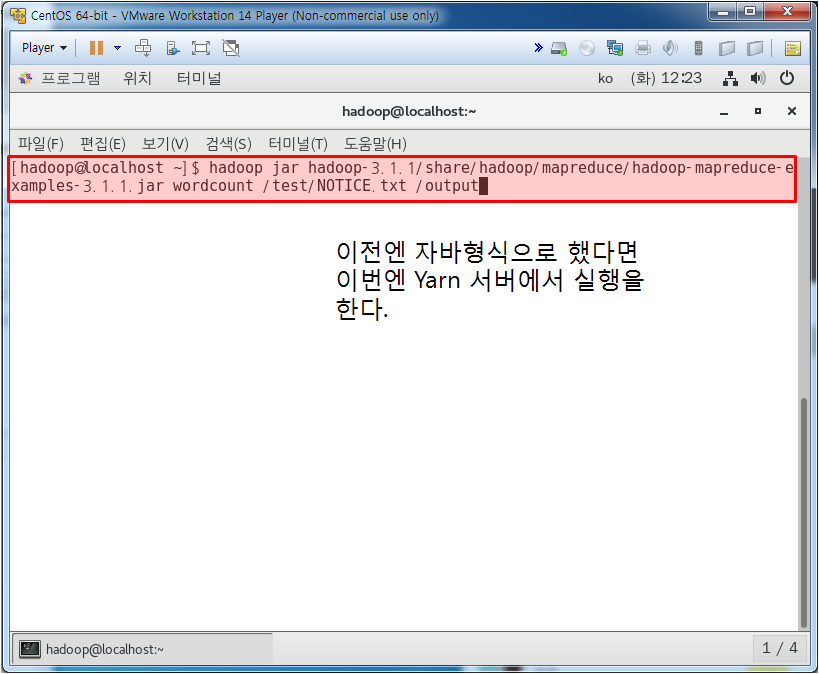

위와 같이 수행되었다.
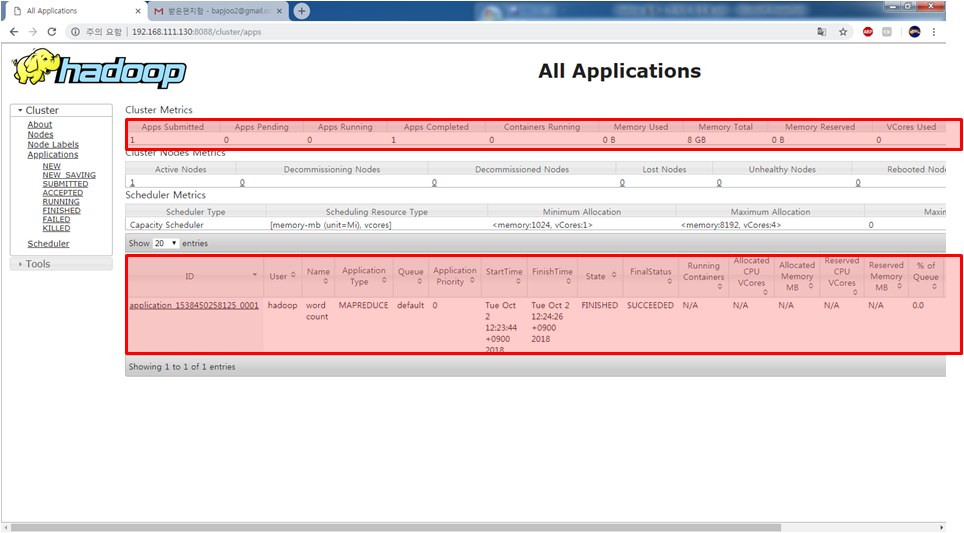
apps 돌아가는 동작이 1이 추가 되었고,
아래 FinishedTime이 뜬걸 보면 동작이 Yarn에서 수행됨을 확인할 수 있다.
output내 결과를 확인해 보자
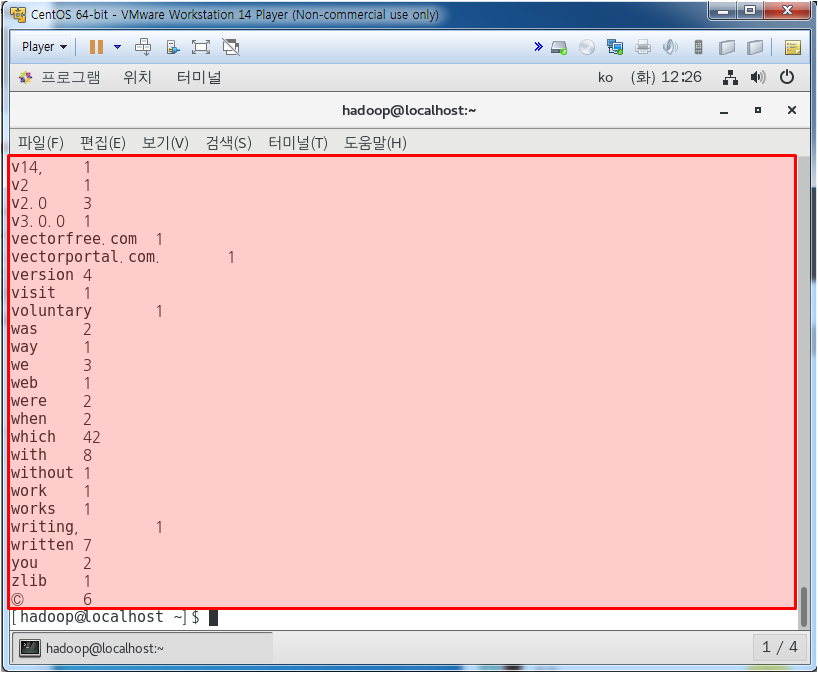
결과를 위와 같이 확인할 수 있다.
'Web & Mobile > Hadoop' 카테고리의 다른 글
| Lecture 93 - Hadoop(3) 3개 서버 연동하기 (0) | 2019.08.13 |
|---|---|
| Linux CentOS에 Hadoop 설치 방법 (0) | 2019.08.08 |
| Lecture 91 - Hadoop(1) 하둡 개념 및 기초 (0) | 2019.08.07 |



댓글